Value Semantics in C++
Back to Basics: C++ Value Semantics - Klaus Iglberger - CppCon 2022
Source: Back to Basics: C++ Value Semantics - Klaus Iglberger - CppCon 2022
Toy Problem: Drawing Shapes
Klaus starts with a simple problem:
we have some shapes, and we want to apply operations to all of them.
For example, we may have Circle and Square, and operations like Draw or Rotate.
At first, this looks like a normal object-oriented design.
We can define a base class Shape, derive Circle and Square, and use the Visitor pattern for the operations.
A Classic Visitor Implementation
First, we define a visitor interface and a base shape class:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Circle;
class Square;
class ShapeVisitor {
public:
virtual ~ShapeVisitor() = default;
virtual void visit(Circle const&) const = 0;
virtual void visit(Square const&) const = 0;
};
class Shape {
public:
Shape() = default;
virtual ~Shape() = default;
virtual void accept(ShapeVisitor const&) = 0;
};
Then each concrete shape inherits from Shape and implements accept():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class Circle : public Shape {
public:
explicit Circle(double rad) : radius{rad} {}
double getRadius() const noexcept;
void accept(ShapeVisitor const& v) override;
private:
double radius;
};
class Square : public Shape {
public:
explicit Square(double s) : side{s} {}
double getSide() const noexcept;
void accept(ShapeVisitor const& v) override;
private:
double side;
};
An operation such as drawing is implemented as a visitor:
1
2
3
4
5
class Draw : public ShapeVisitor {
public:
void visit(Circle const&) const override;
void visit(Square const&) const override;
};
Drawing all shapes means iterating through the container and calling accept():
1
2
3
4
5
void drawAllShapes(std::vector<std::unique_ptr<Shape>> const& shapes) {
for (auto const& s : shapes) {
s->accept(Draw{});
}
}
Finally, the shapes are usually stored behind pointers:
1
2
3
4
5
6
7
8
using Shapes = std::vector<std::unique_ptr<Shape>>;
Shapes shapes;
shapes.emplace_back(std::make_unique<Circle>(2.0));
shapes.emplace_back(std::make_unique<Square>(1.5));
shapes.emplace_back(std::make_unique<Circle>(4.2));
drawAllShapes(shapes);
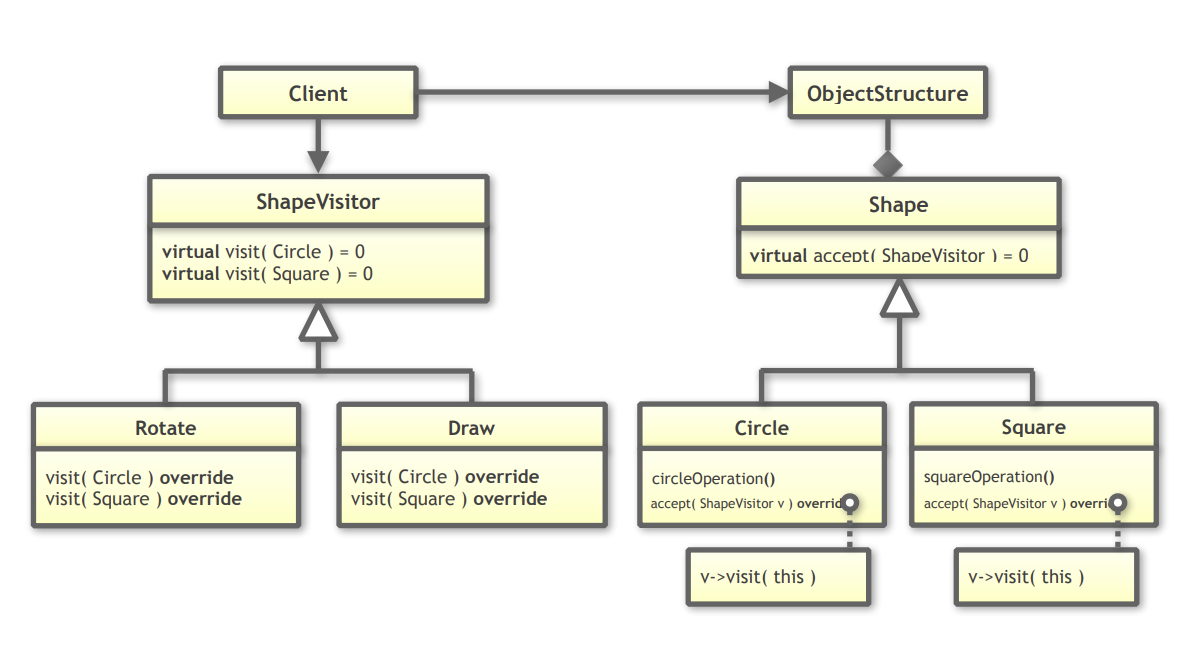 Design of the classic Visitor pattern
Design of the classic Visitor pattern
The design looks roughly like this:
- a base class
Shape- derived classes like
CircleandSquare - every shape implements
accept()
- derived classes like
We need
accept()becausevisit(Circle)andvisit(Square)are overloads.
Overload resolution happens at compile time, so if we only have aShape*orShape&, the compiler cannot know whichvisit(...)to call.That is why we first call
accept().
accept()is a virtual function and is overridden in each derived class. So runtime dispatch selects the correctaccept()implementation, such asCircle::accept()orSquare::accept().Then, inside that derived
accept(), we callv.visit(*this).
Now*thishas the concrete type, so the compiler can choose the correctvisit(...)overload.
- a separate visitor base class
ShapeVisitor- derived visitors like
Draw - every visitor implements
visit(Circle)andvisit(Square)
- derived visitors like
Problems with the classic Visitor setup
Two inheritance hierarchies (intrusive)
Instead of just modeling shapes, we also need to model visitors. So the codebase becomes more intrusive. Every new shape and every new operation starts affecting multiple places.
Two virtual function calls (reduced performance)
The classic Visitor pattern uses virtual dispatch in both accept() and visit(...).
So one operation can involve two virtual calls, which adds indirection and reduces optimization opportunities.
Many pointers (indirection, reduced safety and performance)
Shapes are usually stored through Shape* or std::unique_ptr<Shape>, because Circle and Square have different sizes and cannot be stored directly as one uniform base object.
This adds an extra level of indirection and makes the code less cache-friendly.
Dynamic memory allocation
Once shapes are stored through pointers like std::unique_ptr<Shape>, each object is usually allocated separately on the heap.
This adds overhead and makes the design heavier than the problem really needs.
Many small, manual allocations (reduced performance)
Each shape is often allocated separately, for example with std::make_unique<Circle>.
So instead of one compact block of data, we get many small allocations scattered in memory.
That is worse for both allocation cost and cache locality.
Explicit lifetime management and lifetime-related bugs
Once shapes are stored through std::unique_ptr<Shape>, we must think about ownership and lifetime explicitly.
That adds mental overhead and makes bugs like dangling pointers or use-after-move more likely.
So even though the original problem is simple, the classic Visitor approach adds a lot of machinery: inheritance, virtual dispatch, pointers, heap allocation, and lifetime management. This is exactly the point where Klaus introduces a much simpler alternative: value semantics.
A Value Semantics Solution
Instead of using a base class and pointers, we can represent a shape as a value:
1
using Shape = std::variant<Circle, Square>;
Now Shape is a value that contains either a Circle or a Square.
There is no base class and no inheritance.
The concrete shape classes also become simpler:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Circle {
public:
explicit Circle(double rad) : radius{rad} {}
double getRadius() const noexcept;
private:
double radius;
};
class Square {
public:
explicit Square(double s) : side{s} {}
double getSide() const noexcept;
private:
double side;
};
Circle and Square are now just regular classes.
They do not inherit from Shape, and they do not need accept().
Operations such as drawing can be implemented as a normal function object:
1
2
3
4
5
class Draw {
public:
void operator()(Circle const&) const;
void operator()(Square const&) const;
};
Then we can apply the operation with std::visit:
1
2
3
4
5
void drawAllShapes(std::vector<Shape> const& shapes) {
for (auto const& s : shapes) {
std::visit(Draw{}, s);
}
}
And now the shapes are stored directly as values:
1
2
3
4
5
6
7
8
using Shapes = std::vector<Shape>;
Shapes shapes;
shapes.emplace_back(Circle{2.0});
shapes.emplace_back(Square{1.5});
shapes.emplace_back(Circle{4.2});
drawAllShapes(shapes);
Benefits of the value semantics design
No inheritance (non-intrusive)
The value-semantics solution does not need a base class. Circle and Square stay independent. This makes the code less intrusive.
No virtual functions
std::visit does not require virtual dispatch like the classic Visitor pattern. So we remove the extra virtual calls from the design.
No pointers or indirections
Shapes are stored directly in std::vector<Shape>. We no longer need Shape* or std::unique_ptr<Shape>. The data is more direct and easier to reason about.
No manual dynamic memory allocation or lifetime management
Since shapes are stored as values, we do not need per-object heap allocation, ownership handling, or smart pointers. This removes a lot of complexity.
Better correctness and performance
Because the code is simpler, it is also easier to get right. And since we avoid virtual calls, pointers, and heap allocation, performance can also improve.
Advantages of Value Semantics
- Easier to understand
- Easier to write
- More correct
- Potentially faster
Why reference semantics can be dangerous
std::span
Consider this code:
1
2
3
4
5
6
7
8
9
std::vector<int> v{1, 2, 3, 4};
std::vector<int> const w{v};
std::span<int> const s{v};
w[2] = 99; // compilation error: w is const -> Value semantics
s[2] = 99; // works -> Reference semantics
print(v); // prints 1 2 99 4
Here, w uses value semantics. It is a constant copy of v, so changing w would not affect v. That is why w[2] = 99 is not allowed.
But s uses reference semantics. It does not own its own elements. It only refers to the data inside v. And since s is const, we cannot change which vector it refers to, but we can still modify the underlying elements through s because they are not const.
If we want a read-only view, we should use:
1
std::span<int const> const s{v};
But this is easier to get wrong, because the constness of the span and the constness of the elements are different.
std::spanis reasonable as a function argument, but dangerous to store for longer.
Another example:
1
2
3
4
5
6
7
8
std::vector<int> v{1, 2, 3, 4};
std::span<int> const s{v};
v = {5, 6, 7, 8, 9}; // may reallocate
s[2] = 99; // still compiles, but now UB
print(s);
Here, s refers to the elements of v.
If v reallocates, s may still point to the old memory.
So s[2] = 99 still compiles, but the program now has undefined behavior.
The span looks valid, but it is actually dangling.
This is the main danger of reference semantics here. The object itself looks small and harmless, but its correctness depends on the lifetime of something else.
Reference Parameter
1
2
auto const pos = std::max_element(begin(vec), end(vec));
vec.erase(std::remove(begin(vec), end(vec), *pos), end(vec));
At first, this code looks fine. We first find the maximum element, then remove all occurrences of it.
But there is a subtle problem here. std::remove takes the value to remove by reference:
1
2
template<class ForwardIt, class T>
constexpr ForwardIt remove(ForwardIt first, ForwardIt last, T const& value);
So in this call, *pos is passed as a reference, not as a copied value.
That means the algorithm is using a reference to an element inside vec itself. But std::remove also moves elements around inside the same vector. So the referenced value may change during the algorithm.
This is the danger of reference semantics again. The code looks simple, but the result depends on aliasing through a reference.
A safer version is to use value semantics:
1
2
3
auto const pos = std::max_element(begin(vec), end(vec));
auto const value = *pos; // copy the value, not a reference
vec.erase(std::remove(begin(vec), end(vec), value), end(vec));
C++ takes value semantics seriously! (Dave Abrahams)
Examples from the Standard Library
There are further examples for value semantics from the Standard Library:
- The design of the STL (C++98)
std::optional(C++17)std::expected(C++23)std::function(C++11)std::any(C++17)
The design of the STL (C++98)
Containers are values
In the STL, containers are designed as values.
That means copying a container implies a deep copy.
Consider this code:
1
2
3
4
std::vector<int> v1{1, 2, 3, 4, 5};
std::vector<int> v2{};
v2 = v1;
After the assignment, v2 gets its own copy of the elements. The two vectors do not share the same storage. Each vector owns its own data.
This is exactly what value semantics means here. A container behaves like an independent value. Copying it creates another independent value.
A shallow copy would be a bad idea. If two vectors shared the same underlying data, the code would become much harder to reason about. Changing one vector could unexpectedly affect the other.
So the STL chooses the simpler rule: containers are values, and copying means deep copying. This makes their behavior more predictable.
Algorithms take arguments by value
Many STL algorithms follow value semantics.
They often take their arguments by value instead of storing references to external objects.
For example:
1
2
3
4
template<typename InputIt, typename OutputIt, typename UnaryPredicate>
constexpr OutputIt copy_if(InputIt first, InputIt last,
OutputIt d_first,
UnaryPredicate pred);
Here, the predicate is passed by value. So the algorithm works with its own copy. It does not depend on some outside object staying alive.
This fits the general STL design. Values are easier to reason about. They are more self-contained, and usually safer than hidden references.
std::optional (C++17)
There are many possible designs for to_int():
1
2
3
4
int to_int(std::string_view s); // return default on error
int to_int(std::string_view s); // throw on error
bool to_int(std::string_view s, int& out); // return success flag
std::unique_ptr<int> to_int(std::string_view s); // return null on error
But a much cleaner design is:
1
std::optional<int> to_int(std::string_view s);
This means the function either returns an int, or returns no value. It is simple and direct.
This is a good value-semantics design:
- no question of ownership
- no pointer involved
- no exception overhead
- efficient because of RVO and move semantics
The main limitation is that std::optional can only say success or failure. It cannot explain why the failure happened.
std::expected
A better version of std::optional for error handling is std::expected.
It still uses value semantics, but now it can also store the reason for failure.
For example:
1
std::expected<int, std::string> to_int(std::string_view s);
This means the function either returns an int, or returns an error message as a std::string. So it keeps the same simple value-based design, but carries more information than std::optional.
It also has the same main benefits:
- no question of ownership
- no question of semantics
- no exception overhead
- efficient because of RVO and move semantics
So compared with std::optional, std::expected is useful when failure should carry an explanation.
std::function
If we want an abstraction for callable objects, we usually do not build an inheritance hierarchy for that.
For example, we would not usually write something like this:
1
2
3
4
5
6
7
8
9
10
class Command {
public:
virtual void operator()(int) const = 0;
};
class PrintCommand : public Command {};
class SearchCommand : public Command {};
class ExecuteCommand : public Command {};
void f(Command* command);
Instead, we would simply write:
1
void f(std::function<void(int)> command);
This is much simpler. std::function gives a value-semantics abstraction for callable objects:
- no inheritance hierarchy
- no pointers
- no manual lifetime management
- less code
So once again, value semantics gives a cleaner design. We keep the abstraction, but avoid the extra machinery of inheritance.
Takeaways
Value semantics:
- will make your code (much) easier to understand (less code).
- will make your code (much) easier to write.
- will make your code more correct (as you avoid many common bugs).
- will (potentially) make your code faster.
So the main takeaway from this talk is simple: prefer value semantics over reference semantics when it fits the problem.